








 Page
Page
Why RAG is Difficult to Scale
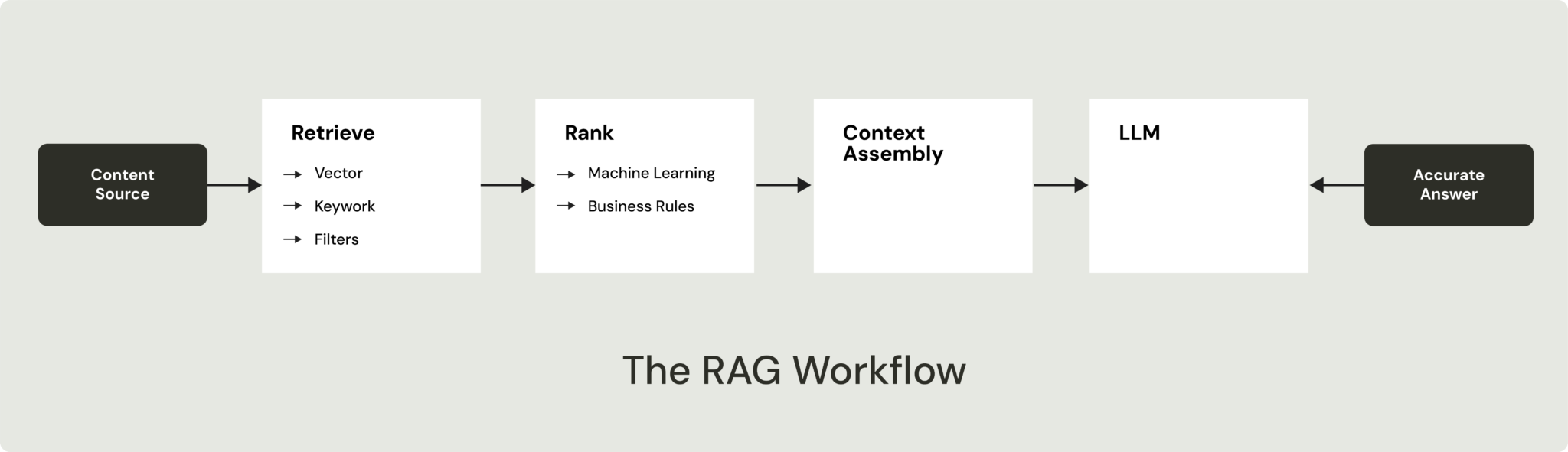
Retrieval-Augmented Generation (RAG) is the standard for grounding large language models with external knowledge. Early RAG applications combined embeddings, a vector database, and an LLM. As these applications mature, however, the retrieval workflow becomes significantly more sophisticated.
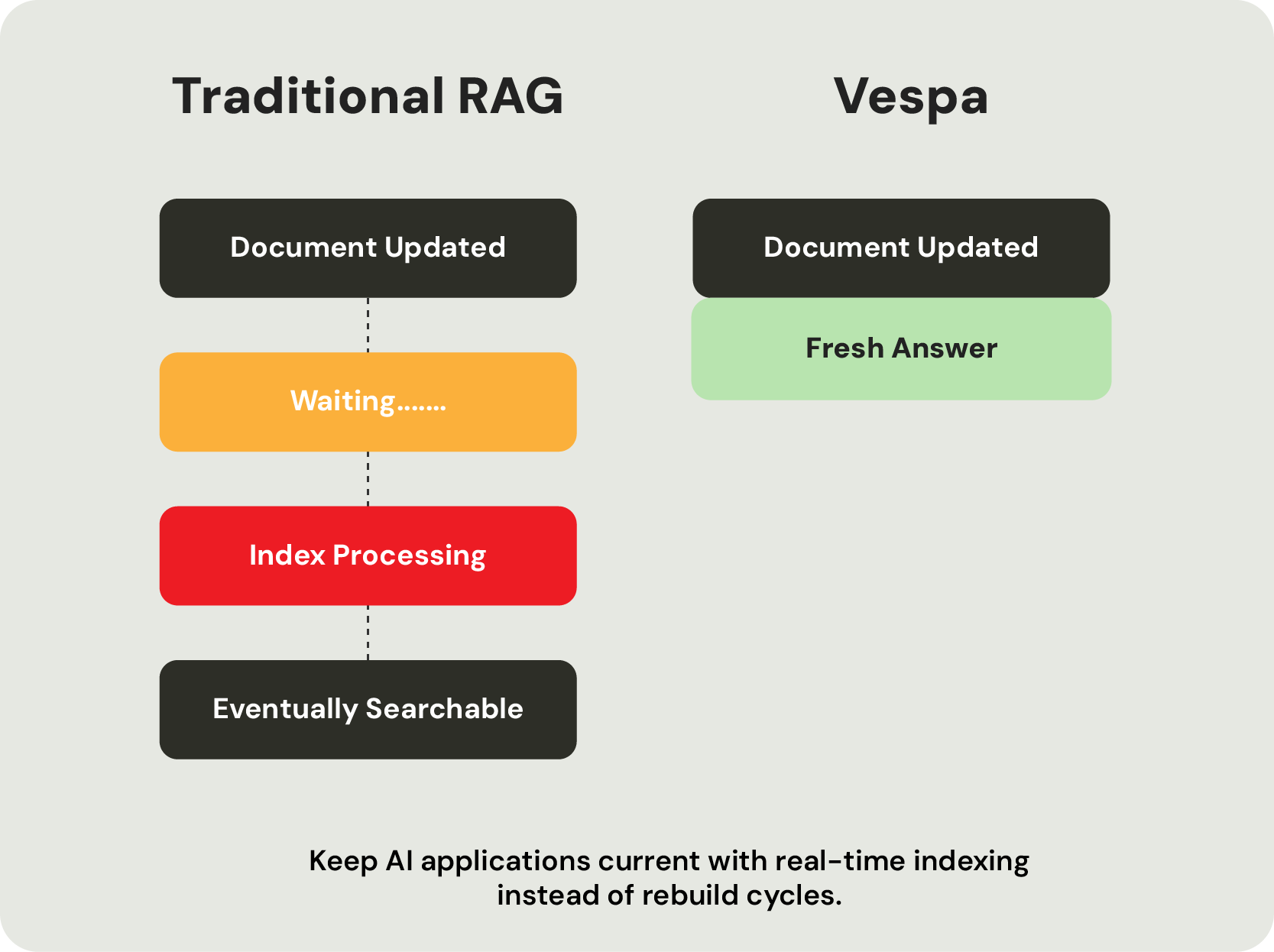
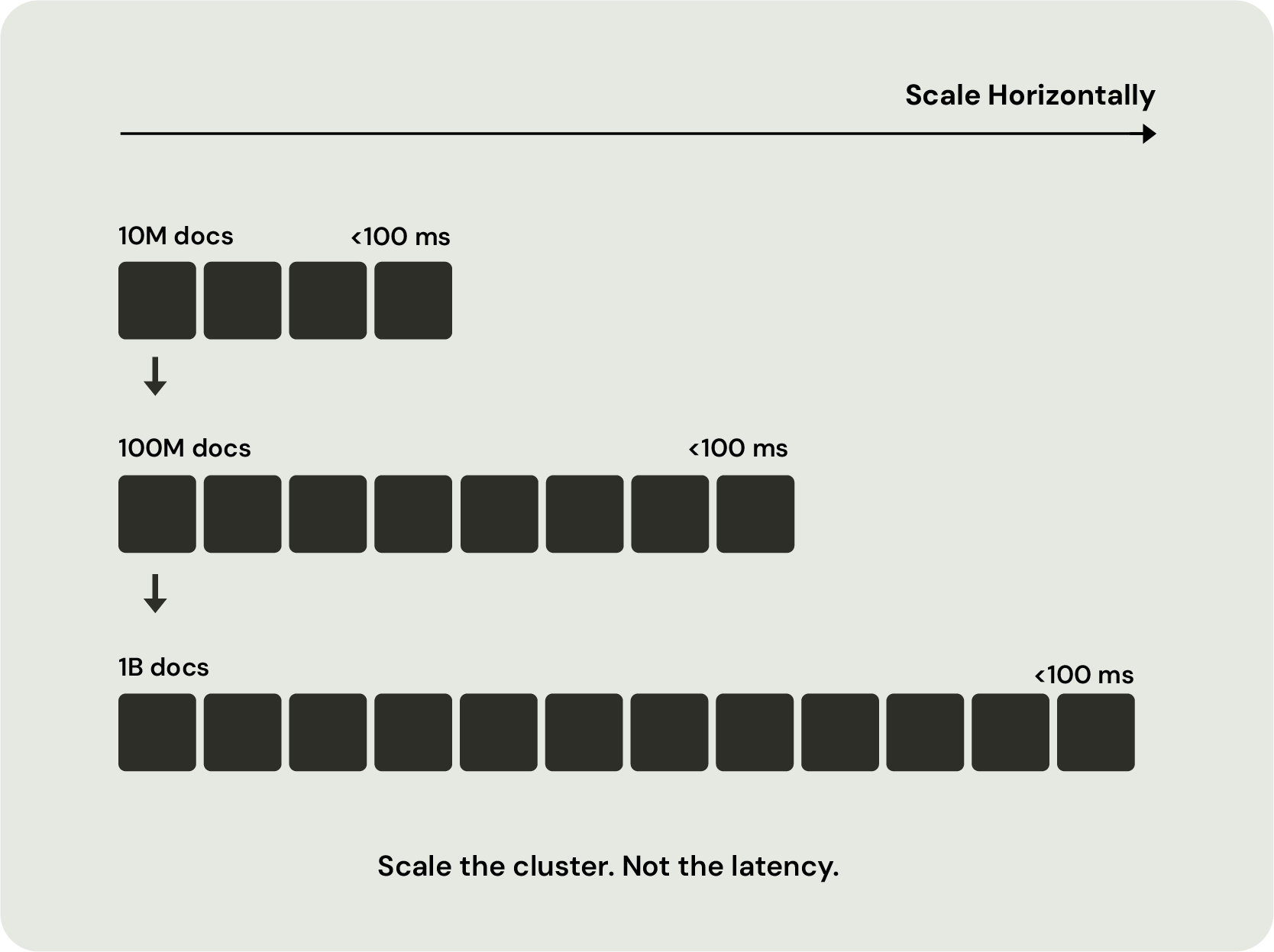
Improving answer quality often means adding hybrid retrieval, structured filtering, reranking, business rules, real-time updates, and machine learning inference. What begins as a simple RAG application gradually becomes a complex retrieval workflow spanning multiple specialized systems, increasing infrastructure cost, latency, and operational complexity. The rise of agentic AI compounds this problem, dramatically increasing retrieval volume while placing even greater demands on latency, freshness, and ranking quality.
Where retrieval workflows power customer-facing AI applications, every retrieval decision directly affects answer quality, response time, and user trust. Unlike traditional search, where users can compensate for imperfect ranking by selecting a better result, the language model can only answer using the context it receives.

